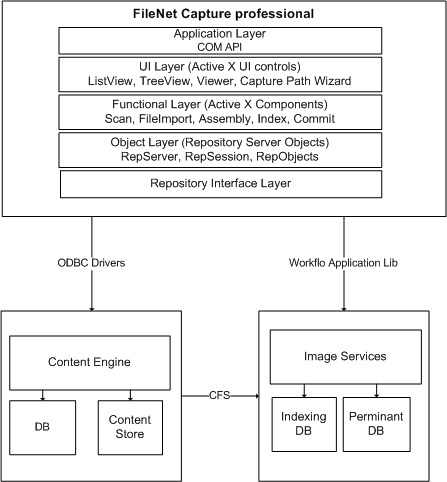
Definer features an interface that allows configuration changes to be made quickly and includes an embedded Recognition engine that allows the effect of changes on the recognition process to be tested immediately.
There are two different types of processes available to configure the form definition.
1. Fixed Form
2. Free Form
Fixed Form is used to configure the structured documents while the Free Form is used to configure the unstructured or semi-structured documents.
Below I have explained about the Fixed Form configuration. In the Fixed Form we need to define the fields and registration points which are became a reference points for the recognition to extract the data.
There are 2 different configuration files are used in the Definer.
1. Definition File (.idf)
2. Script File (.ifv)
Important Terminology:
Fields: An item of data that is to be captured is called a field. Fields can be of the following types: single line text, multi-line text, mark sense, mark grid, table or bar code.
Registration point: It is feature on the document used to recognize the document type. The position of all data fields is defined relative to the registration points. Registration point can be a corner mark, blob (for example logos), line and text.Segmentation: It is the process of separating the text, marks or barcodes to be recognized from the background of the form and separating a field of text into individual characters.